本文对 open-vocabulary model 进行一些复习跟梳理。
Open-vocabulary models
一般而言,传统的 NLP 使用 one-hot 编码来对词汇进行处理。但是,通常而言自然语言的词汇表会非常庞大,这会直接导致我们的网络结构过于复杂,训练速度变慢。在翻译领域,这一表现尤其明显:首先,翻译的语料库往往包含大量的单词种类;而且在生成单词过程中,我们需要处理未见过的单词;另外名字,数字等通常有着简单的形式,但是他们自身是开放的单词类(open word classes)。因此,我们需要 open-vocabulary model 来解决庞大乃至无限大的词汇空间。
我们可以简单地将不在词汇表里的单词用一个 out of vocabulary (unk) 符号来表示。如果我们单从单词覆盖率的角度来看,需要用 unk 代替的稀有词汇其实不多 (5% for 50000 words)。但是这些词汇往往包含很多信息,比如说人名,地名,专有名词等等,而这些信息的缺失在翻译中是致命的。
Approximative softmax
在一个“激活”的词汇表子集上做 softmax 处理。在训练时,神经网络的输出端是原有的目标词汇表的一个子集,更新梯度的时候只处理在子集中正确的结果,然后在使用的时候在整个目标词汇表上计算单词的概率。这个方法能够使得使用更大规模的目标词汇表成为可能,但是有两个问题:1. 这个方法实际上不是 open-vocabulary 的;2. 对比较稀有的词汇,这个网络难以学习到正确的表示。
Back-off model
我们在训练的时候依然使用 unk 来替代稀有的词汇,但是在系统生成 unk 后,对 unk 符号做对齐以映射到源语言的单词,然后用 back-off 方法(根据词汇表逐词翻译等)来对映射的单词进行翻译。这个方法同样有很多的问题:1. 很难处理一对多的关系;2. 难以处理词形(inflection);3. 如果目标语言与源语言的字母表不同(中文,英文),需要一套转写名字的系统;4. 对齐方面,attention 不一定总是可靠的。
Subword-NMT
Subword-NMT 的思路是,将单词拆开来成为 subword, 然后使用一些 NMT 的手段处理 sub-word。比如,我们如果要对特朗普做翻译:
- 英文:Trump
- 中文:特朗普
- 日文:トランプ
而对于数字,专有名词等,我们在人工翻译的时候往往也是逐 subword 翻译。
我们希望 open-vocabulary 系统能够:
- 用一个相对小的词汇表编码所有的词
- 能够在未出现过的单词上泛化良好
- 需要比较小的训练文本
- 相对的,有较好的翻译质量
Byte-pair encoding for word segmentation 字节串编码
字节串编码的基本思路是使用一个新的、不在词汇表里的符号来替代原来字符串里经常出现的符号。
我们首先将单词表示为字母组成的序列,然后使用字节串编码对其进行压缩,压缩后的子字符就是我们的新的词汇表,我们可以使用超参数来控制词汇表的大小。
BPE 的算法简述如下:
- 初始化符号表,先将所有的字母放到符号表中,然后将每个单词表示为符号序列。每个单词的结尾符号使用特殊的符号来标注,使得我们可以重建单词(e.g. 词尾的 w 与 词中的 w 不一样)
- 迭代地计算所有的符号对,将出现次数最多的符号对替换成为一个单独的符号,比如
('A', 'B')会被换成('AB')这个操作每次相当于创建了一个 n-gram 的编码。同理,('AB', 'C')会被换成('ABC')。迭代多次,可以将出现频率最高的 n-gram 编码成为新的符号 - 我们将新合并的符号放入原有的词汇表,最终的词汇表大小为原有的大小+合并操作次数
举例,我们在原有的词汇表里面有如下单词,分别出现若干次:
low:5 lower:2 newest:6 widest:3
现有的词汇表如下:
l o w<\w> w e r<\w> n s t<\w> i d
观察我们的训练数据,我们可以发现 ('e', 's') 是出现次数最多的(9+3),于是我们使用 ('es') 代替。迭代地,我们发现('es', 't</w>') 出现次数最多,于是我们也将其编码为 ('est<w/>'),词汇表变为:
l o w<\w> w e r<\w> n s t<\w> i d es est<\w>
再一次迭代,最多的符号对变成了 ('l', 'o'), 而不是 ('w', 'est<\w>')/('d', 'est<\w>')。于是符号表变为:
l o w<\w> w e r<\w> n s t<\w> i d es est<\w> lo
使用 BPE 的编码方法比 back-off 会有大概 5% 左右的提升(BLEU分数), 而且在稀有词的表现更好。
如果我们将源语言与目标语言的 BPE 合并处理会有更好的一致性。而分开处理,有可能导致同样的名字在不同的语言中被不同地分割,从而影响一致性。
If we apply BPE independently, the same name may be segmented
differently in the two languages, which makes it
harder for the neural models to learn a mapping
between the subword units.
Character-level models
- 优点:
- open-vocabulary
- 不需要启发性/language specific 分割
- 神经网络可以从字符串序列学习
- 缺点:
- 序列长度增加导致训练与解码的耗时增加(2-8倍)
- open-questions:
- on which level represent meaning?
- on which level attention operate?
Hierarchical model: back-off revisited
在单词层面,使用 UNK 替代, 对于每一个 UNK, 使用 character level model预测单词,基于单词的 hidden state。
- 比查字典更灵活
- 比纯 character-level 翻译有更好的准确性
- main model 与 back-off model 之间有独立的假设(Markov?)
Character-level output
- 目标语言单词不需要分割,使用 character-level 表示(i.e. 字符序列)
- encoder 使用 BPE-level 词汇表
- EN -> {DE, CS, RU, FI} 有较好表现
- 训练时间长
Character-level input
- 输入层面不做分割,使用 character-level 的表示
- 使用 character-level lstm 来计算字符序列的向量形式
Fully Character-level NMT
- 跨单词处理
- 目标语言端使用 character-level RNN
- 源语言端:CNN + max-pooling
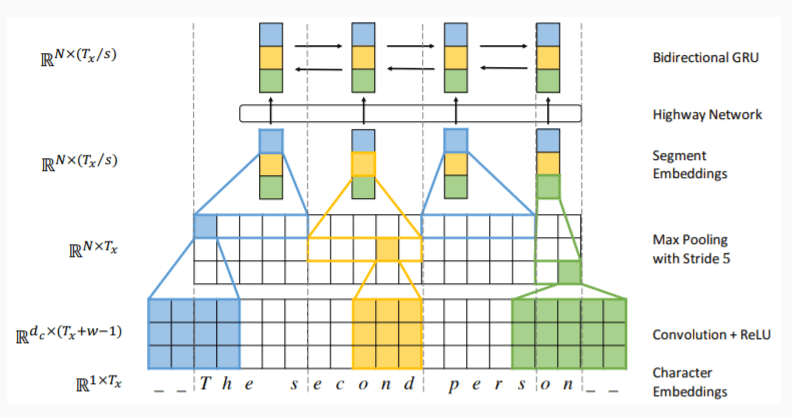
Large-capacity character-level NMT
- 训练深度 attentional LSTM encoder-decoder
- 浅层模型:BPE
- 深度模型:character-level 模型更好
- 主要的问题是训练时间过长
- 主要的挑战:在保证质量的前提下压缩表示方法
Morphology
单词根据词法,会有不同的变化:
- 词形(inflection)
- case (格)
- 数量(number)
- agreement
对于英语来说:
- case
- number
- person
- tense
… 总之 词法很复杂
在书写系统中,我们定义 morpheme 为最小的对意义造成影响的单位
- free morpheme: 独立地作用, dog/house
- bound morpheme: 只作为单词的一部分出现: un-, -ed, -ing
对于中文而言,偏旁部首也作为 phoneme 存在
原则上来说,subword/character-level 模型能够学习到词法生成的规则,但是在实际上从文本中学习到词法是很困难的:
- subword 不一定是 morphoneme
- 有关联的词的形态不一定相似: stand-stood
- 词法上,语言所表示的含义可能不同
另外,语言学的研究提供了很多词法规则可以直接拿来使用。一种最基本的方法是直接用字典形式+前后缀来替代输入中的一些变化的词(lemmatize)
Morphology on Source side
对于输入而言,我们可以将原本的单词向量替换成单词向量+字典形式向量(lemma)拼接后的向量。
Morphology on Target side
2-step 翻译: 首先用主系统预测字典形式的单词,然后将字典形式的单词使用基于统计的词形转换系统进行预测
2-step NMT:首先交叉地预测字典形式单词与词法类别,然后使用有限状态转换器(finite state transducer)来处理词形变换
Neural Inflection Generation
输入为单词的字典形与词法参数(时态,数量,格等),使用 encoder-decoder 模型来预测转换后的单词
Information missing in source, case study: Politeness
在英语里,you 没有普通用法与尊敬用法的区别,但是在很多其他语言中,这样的区别存在。将英语翻译成别的语言的时候,我们需要判断何时应当用普通形,何时应当用敬体形。
解决问题的主要思路如下:
我们需要根据目标端的一些额外信息:在目标语言的语境中是否礼貌,将其作为一个额外的标注拼接在源语言序列后面。在测试的时候,我们可以控制输入是否礼貌。i.e. 对输入增加一些源语言中不存在的信息的标注。
同样的思路可以应用到时态,evidentiality,领域适配,对输出语言的控制等等。