Dependency Parsing
传统的语法模型通常是成分式 (constituent structure) 的:把句子看作是不同成分的组合。
成分解析法通常将一个句子组合成一棵树,树的叶节点是终结符(单词),其上所有的非叶节点表示语法结构。举例:
Sentence | +-------------+------------+ | |Noun Phrase Verb Phrase
| |
John +———-+————+
| |
Verb Noun Phrase
| |
sees Bill来源: 知乎
但是成分解析在语义的方面比较弱。以上面的解析树为例,对于动词 sees, 我们关心的是它的主语跟宾语,但是在成分解析树中,主语 John 跟宾语 Bill 都被当成 NP 处理,语义上的关联性需要去处理许多的语法成分节点。因此,我们引入依赖(dependency)。
在 dependency parsing 中,每个单词都将根据它们之间的关系连接起来形成一张有向图,图的每一个节点都是每一条边都表
示依赖关系。比如上例的 dependency parsing 树可以画为:
Root —-> sees —- (obj) —-> Bill
|+ ----- (subj) ---> John
一棵 dependency parsign 树由如下部分组成:
- Head
- Dependent
- Label identifying H and D
Parsing Techniques
对于 consistuent parsing 来说,通常使用一些诸如 CKY,shift-reduce parsing 的算法来进行 parsing。 但
是,这些方法往往以来临近的单词,而 dependency parsing 通常会依赖于非邻接的单词。我们通常用两种算法来进行这
种 parsing: maximum-spanning trees(MST) 以及 transition-based dependency parsing (MALT) 。
我们的目标是:在所有可能的依赖树(dependency parsing)空间内,寻找到一棵最优的树。
令 为输入的单词序列,为边(dependency edge)的集合。令定义为单词 到 的边。
由于每个词都有唯一一个父节点,这个问题同 tagging problem 很类似:每一个词都用句子中的另一个词来做 tagging。如果我们进行对整棵树进行边分解(edge factorize),定义树的得分为所有边的乘积,我们可以简单地直接选取每个词有着最高分数的边,只要我们满足所有的边最后能够组成一棵树的约束。
我们定义一条边的分数为一个函数 ,依赖树的分数为:。我们 parsing 的目标是,给定句子 x, 选取有最高分数的树 y 。
MST 与 Chu-Liu-Edmonds(CLE) 算法
MST 算法可以表述成如下过程:
- 我们假定一个全连接图 G,使得句子中每个单词都与其他单词互联,任意单词对都有一条边建立。
- 定义评分函数 s
- 在 G 中,找到一棵 MST,使得树有着最高的分数且包含了所有的 node,这棵树即为最佳的 parsing tree
使用 Chu-liu-Edmonds 算法,能够在 的时间内找到一棵 MST, 但是不保证这棵树是 projective 的。
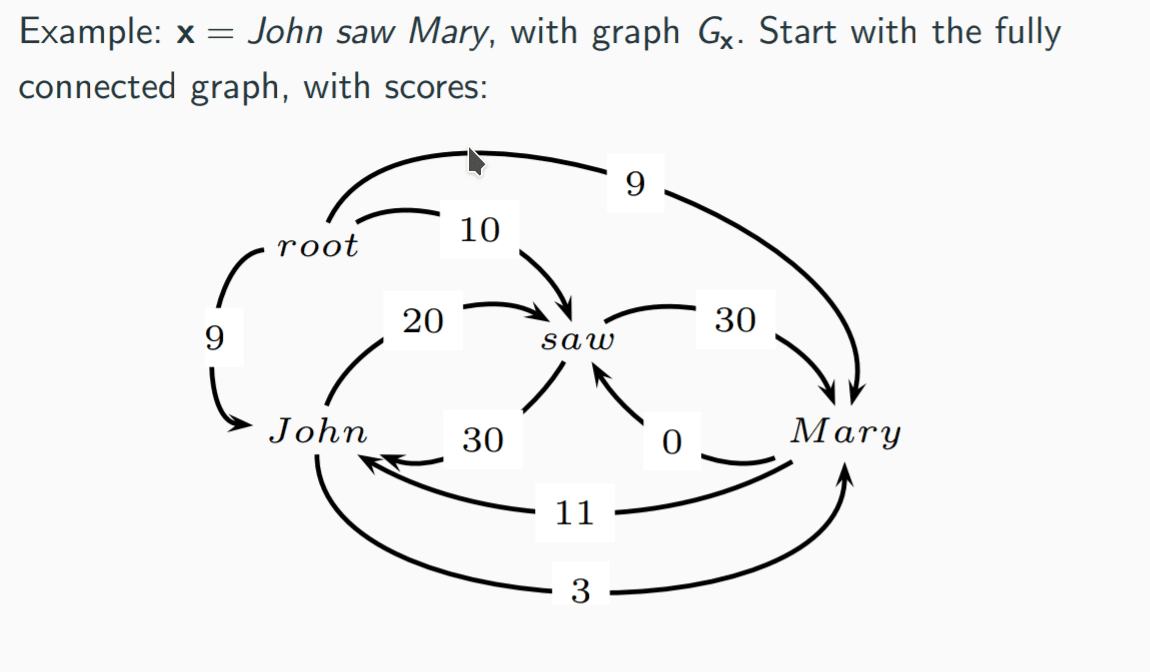
如上图,这是一张已经评完分的全连接图。
首先,对于图中的所有节点,选择一个有着最高分的入边(incoming edge),形成新的图

如果这一步生成了一棵树,那么这棵树就是 MST,如果存在不连通的点则无解。第三种情况必然有环的存在。
对于环而言,我们将每个环“缩”成一个等效的点,并且重新计算这个等效点入边与出边的权重。
根据这篇文章
的解释,我们需要寻找环内的一条边打断。这个打断的过程等于消除了环上一个节点的入边,以次优的入边(最大或者最小)取代之,取打断后最优的选项,进行打断,从而消除环。如上图, John 与 saw 形成了一个环,我们要将这个环替换成一个等效的点,可以打断的选项有 (John, saw) 与 (saw, John)两条边。对于每一种打断方式而言,环会形成一条链。由于我们将环缩成了等效的点,外部的入边到环的权重变为:从该边指向的节点作为链的起始,直到链的结尾的所有入边的权重之和。
我们重复以上步骤直到只有一个点,然后按照我们的打断法展开成树,就可以得到 MST。
对于打分函数而言,我们可以选用设计好的SVM MIRA 等,最近使用神经网络的比较多。对于神经网络打分函数,我们定义函数值为给定句子与父节点,连通子节点的概率
其中,向量是通过前向-后向 RNN 生成的。函数 g 计算相关性分数,一个简单的实现为:
我们可以看出,相关性分数的形式与之前提到过的 Attention 的计算方式很像。
RNN-based Grammar
自然语言的语法很大程度上是有层级的(hierarchial)。如果要使用 RNN 来对语法进行建模,我们需要对此进行考虑。
RNN语法(RNNG)的一般操作如下:
- 使用 RNN 生成序列的符号(generate symbols sequencially)
- 周期性的使用一些“控制符号”(control symbols)来重写历史
- 周期性的将序列“压缩”(compress)成一个单独的成分(constituent)
- 增强(augment?) RNN 使其能够将最近的历史压缩成为一个单独的向量(reduce)
- RNN 通过历史(包含压缩后与非压缩的单词)来预测新的符号
- RNN 同样要预测控制符号,来决定压缩成分的大小(size of constituent)
与普通的 RNN 相比, RNNG 会生成一棵语法树。
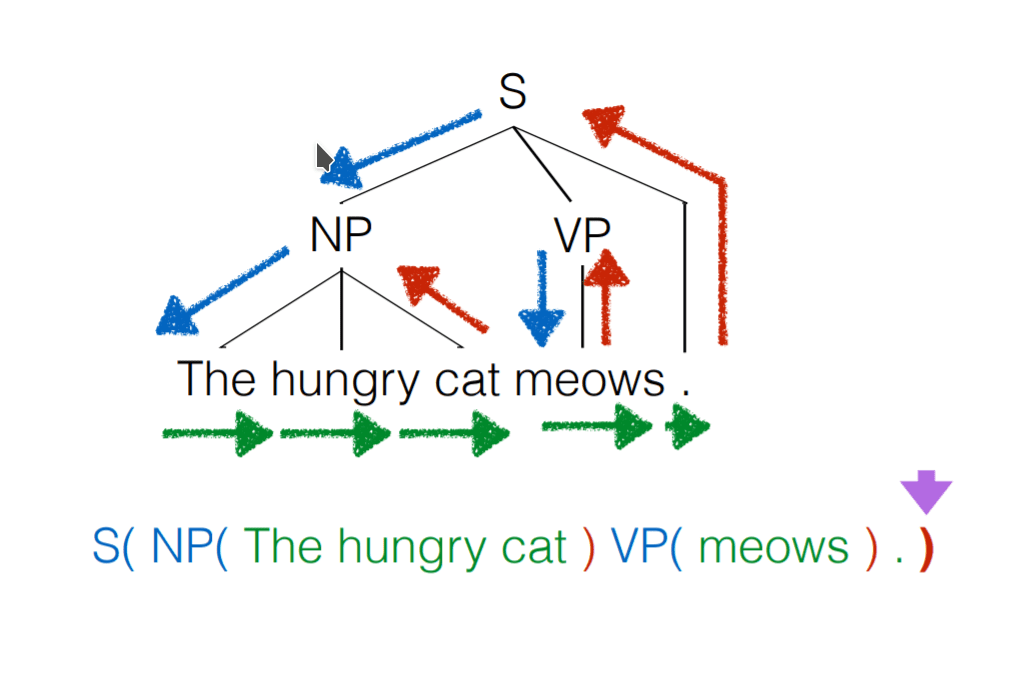
实际上 RNNG 相当于 RNN-based 的 probablistic pushdown automata(下推自动机)。
从这个角度考虑,RNN 需要对如下内容进行建模:
- 之前的 terminate symbols(单词,标点等)
- 之前的操作
- 当前的 stack 状态。
RNN 根据以上信息来预测下一步的操作(nt, gen, reduce 等),如下图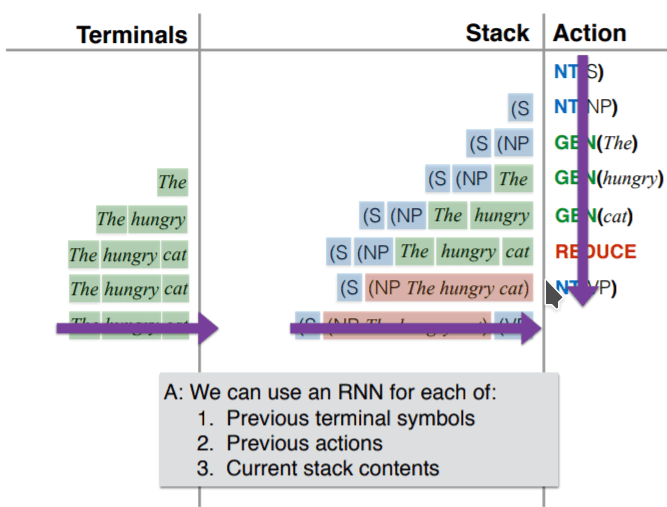
当最后整个句子被处理完毕后,最后在 stack 中剩下的内容就是整个句子语法树的向量形式。
这里我们比较关注的是 reduce 的处理方式。假设我们要对下句进行处理:
(NP The hungry cat)
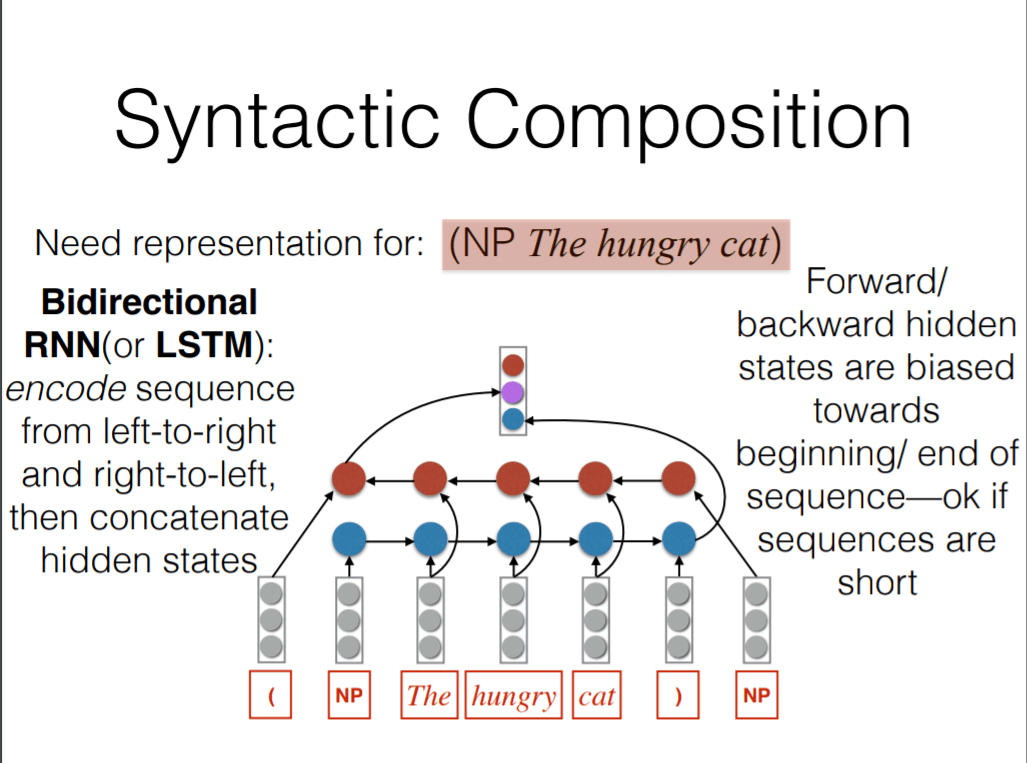
如图,我们使用双向 RNN/LSTM 来处理。NP 定义为语法符号的向量,括号定义为当前序列的终结符,每一个符号都用向量进行表示。BI-RNN 从左到右与从右到左两个方向进行编码,然后将两个方向的信息综合起来输出成一个向量,用来表示部分语法元素。同样的,这个输出后的向量同样可以当成普通的符号进行处理,这样我们就可以递归的解析整棵语法树。
对于 terminal 而言,我们可以发现较前面的序列是后面的序列的前缀,所以可以很轻松地使用 LSTM 来处理。但是对于 stack 而言并没有这层关系。我们使用 stack RNN 来处理这样的栈:我们给 RNN 添加一个栈指示器,这样的 RNN 可以进行两步操作:
- push: 读取输入,将其放在栈最上面,与当前的栈指示器的位置拼接起来
- pop: 将栈指针指向当前的父元素
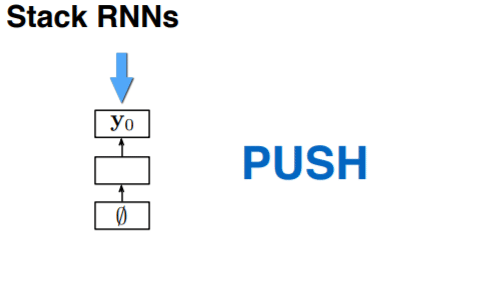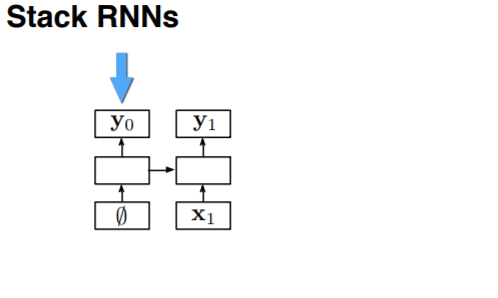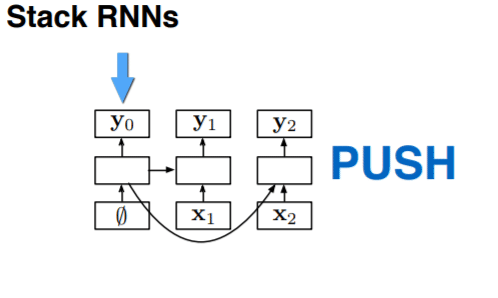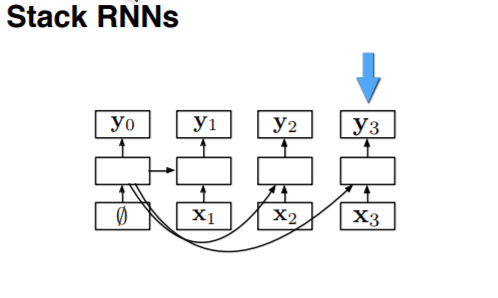
上图展示了 stack RNN 的运作方式。(问题:这里的连接是指的时间序列还是单纯的连接?我觉得应该是时间序列,在时间轴上可以将RNN看做一个链表)下面是 stack RNN 的实际运用。
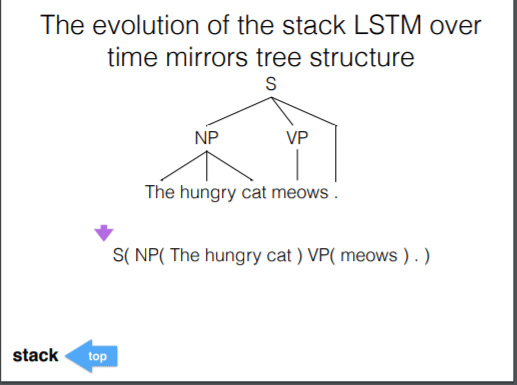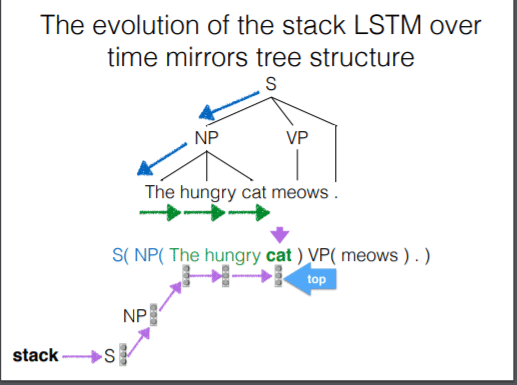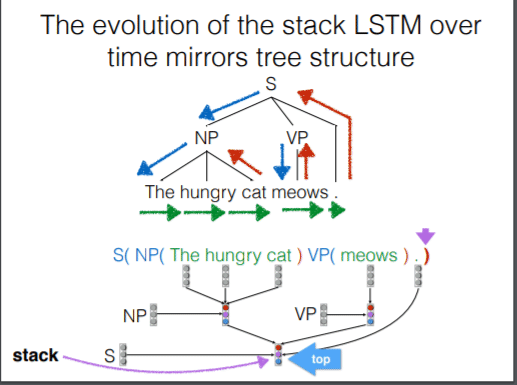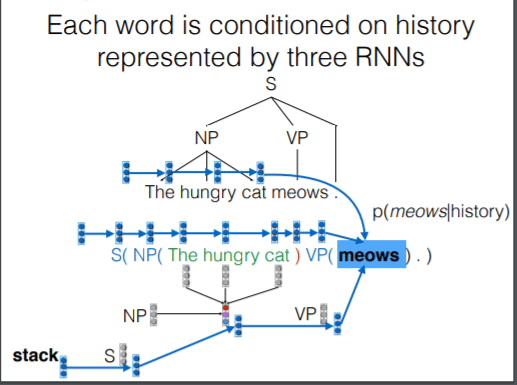
到现在为止我们有 3 个 RNN:第一个 RNN 用于对句子进行建模,第二个 RNN 用于对语法符号序列进行建模,第三个 stack RNN 用于对 pushdown automata 的栈进行建模。每一次预测下一个符号的概率都是由三个 RNN 的信息进行综合。
具体的模型如下:
其中,r是动作嵌入向量,u是历史摘要向量,x是句子,y是树的向量表示。历史向量由三个 RNN 向量拼接而成。
Semantic Role Labeling 语义角色标注
语义角色标注是对句子中的语义成分进行有逻辑性的标注的技术。举例,对于“发送”这个动作而言,有如下要素:
- 发送者
- 接收者
- 发送的东西
- 来源(位置)
- 目标(位置)
SRL 的目标是将这些逻辑要素进行标注,以进行进一步处理。
一个语义可以有多种表述方式,比如说如下句子:
The marmable was shipped by Sam
Sam shipped the marmable
他们在语义上的表述是相同的,但是拥有不同的语法结构。
我们用帧语义来定义语法结构:
- 帧用来描述原型状况(prototypical situation?)
- 使用帧唤起元素(frame evoking element)来唤起帧
- 帧包含若干帧元素,包括语义角色(sem roles)与参数(arguments)
我的理解是,帧就是将句子分割成有机的语义元素的东西。
帧语义有如下性质:
- 提供了浅层语义的分析(非情态,范围)
- 在 universal 与 specific 之间的粒度
- 能够在大多数语言中泛化良好
- 能够作为许多其他应用的基础
我们通常使用 proposition bank 里提供的分类来标注。
一般而言,传统 SRL 包含如下步骤:
- 训练语料的解析
- 将帧元素与句子成分作匹配
- 从解析树中抽取特征
- 根据特征,训练概率模型
Deep bi-RNN/LSTM 方案
输入:已经标记了谓词的句子
输出:对句子的帧语义标注
由于 SRL 是一个序列标注任务,我们同样可以使用 RNN/LSTM。
目前应用的比较广的技术是直接使用深度双向RNN/LSTM进行端到端的语义标注。
- 不使用外部语法信息
- 不需要额外的帧对应步骤
- 不需要特征工程
给定输入句子,我们设计一个输出序列的概率模型:
y 是标注序列, x 是输入序列,输入的特征为当前的单词与谓词的位置。
网络架构如下图:
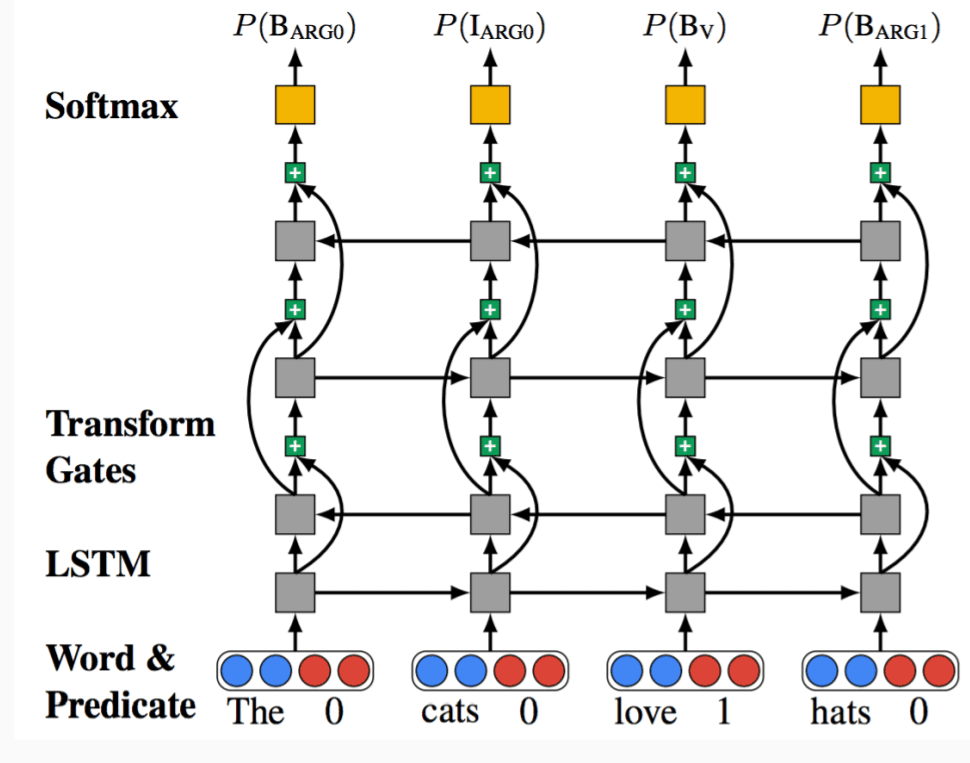
该图的 DB-LSTM 是 LSTM 的一种变种。 bidirectional LSTM 一般包含两层,同相同的输入与输出层连接,对同一句子进行双向处理。这里的 bi-LSTM 有所不同,第一层 LSTM 的输出是第二层反向 LSTM 的输入,这实际上将多重 LSTM 堆叠起来形成了深度学习网络。