Sequence-to-Sequence Model
首先我们来看一下语言模型与翻译模型的区别:语言模型是给定前面的序列,求解当前单词的概率分布;而翻译模型则不然,翻译模型是给定源语言序列,求解目标语言序列。如果用语言模型的方法对翻译模型建模如下:
会碰到这些问题:
- 我们不关心源语言单词的概率
- 源语言与目标语言的词汇表不同,或者有不同的结构
因此,比起用一个 RNN 建模源语言-目标语言序列,我们通常选用两个 RNN 来对源语言与目标语言分别建模。
Encoder-decoder 模型
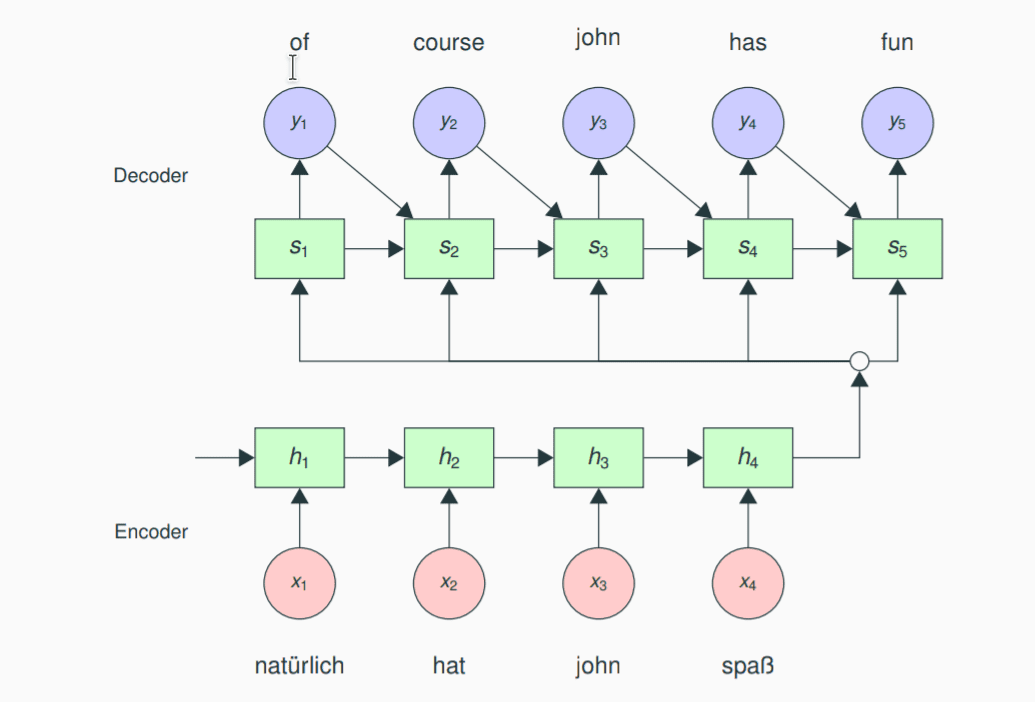
模型分成 encoder 与 decoder 两个部分。首先是 encoder, 他的目的是对源语言句子进行建模。encoder 的输出可以看做是源语言句子的 “摘要”,这个“摘要”我们使用一个中间向量来进行表示。在对多语言进行学习的情况下,这个向量代表着语言无关的语义。在 decoder 端,中间向量作为decoder的第一个输入,用于生成第一个单词;之后使用前面单元生成的词汇与历史信息作为输入,递归的生成整个句子。
使用中间向量来连接 encoder 与 decoder 会出现问题:随着句子长度的增加,固定长度的中间向量表现会变差,一种解决方法是将句子倒过来处理;但是更加有效的优化方法是引入注意力机制(attention)。
注意力机制的作用方式如下:我们使用一层前馈网络来计算源句中每一个单词的权重,然后将每一步 encoder 的输出加权形成一个新的输入向量。对于 decoder 的每一个单词,注意力权重都不同,这样一来我们就可以将源句中的信息分配给比较适合的单词。
注意力机制带来了一个副产物:通过注意力,我们可以某种程度上完成词对齐的工作,但是由于信息流同样递归地流动,实际上不保证注意力机制能够完全替代词对齐。
注意力模型不仅限于处理 NLP 任务,对于视觉任务,e.g. 语义识别等也有一席之地。
Encoder-decoder 模型常见的应用有:
- 给翻译打分: 计算目标句的概率
- 机器翻译
decoding 的一些技术
机器翻译实际上可以看做如下行为:在所有可能的目标语言句空间中,寻找出一个最合适,即概率最高的句子。但是,实际上我们不可能对如此庞大的空间进行搜索,所以我们在 decoding 的时候要采取若干近似手段。
其一,我们可以用从概率分布中采样,或者贪婪的选择当前概率最高的单词,直到生成完结符号。这种方法一般而言不会是最优解。
其二,我们使用束搜索 (beam search)来提升准确率。给定一个 beam size,我们每次搜索的时候,保留一定数量的候选单词,这些单词有着较高的评分或者概率,然后对于每一个候选词汇,我们都往后生成一系列的搜索束,直到搜索序列的长度到达 beam size, 贪婪地选择总体概率最高的序列,重复该过程直到结束。
其三,我们可以用 ensemble 的方式:训练若干个模型,然后在 decoding 的时候,通过投票的方式来选出最佳的翻译。基本的方法是平均(log)概率。一般而言,这些模型共享目标词汇表,以及历史的解码信息,但是训练的方式与网络架构都可以不同。
NMT 的评价方法
NMT 质量的评价方法可以大致分为主观与客观两种。
Metrics:
- Adequacy: 翻译的句子是否与原句的意思相近?
- Fluency: 翻译的句子在目标语言中是否通顺?
Kappa 系数:
p(A) 指评价者评价的概率, p(E)指随机评价的概率
提高一致性的方法还有:
将准确与流畅的评价分开,正则化分数,用一些 trick 将不靠谱的受试者剔除
其他需要评价的一些 criteria:
- speed
- size
- integration
- customization
自动评价
- 目标:程序来评价翻译的质量
- 好处:成本低,易于调整,一致性好
- 基本操作:
- 给定机翻输出
- 给定人类翻译
- 目标:比较两者相似度
precision(correct/output-length), recall(correct/reference-length), f-measure
word error rate: 最小编辑距离除以总长度
BLEU:
n-gram 覆盖率,计算长度为 1-4 的 ngram 的 precision。
首先,计算一个对过短翻译的惩罚:
BP = min(1, exp(1 - ref-length/out-length))
然后计算BLEU:
如果没有 4-gram 能够匹配, BLEU 的值为0。一般而言, BLEU 是计算整个语料库的。
BLEU 同样可以用于计算有多个 reference 的翻译来测试 variability (多样性?)
n-grams 可以匹配任意的 reference, 但是计算的时候用最接近的 ref-length 做计算。
Meteor: 给予词干,同义词一定的分数,paraphrase 的使用也有分。
对 Metrics 的一些批评:
- 无视相关的词
- 通常在本地水平测试,对更加广义的语法不加以考虑
- 分数可解释性不强
- 有的时候人工翻译会得到一个较低的 BLEU 分数
对 Metrics 的评价体系:
与人工判断作比较,计算相关性
Attention 的一些变种
首先,我们看一下多种的计算 attention 分数的方法(Luong et al., 2015):
- 点乘法计算分数
- 一般形式
- 向量拼接的形式:将源语言的输出向量 与上一个翻译的单词拼接起来
Condition
我们还可以把之前的决策纳入考虑(dl4mt-tutorial):
其主要思路是:之前的 Attention 模型只与隐层 s 相关,但是真正决策的单词也会影响之后的概率。
Guided Alignment Training(chen et.al., 2016)
基本思路:
- 使用外部的工具创建词对齐向量(word alignment)
- 如果多个源单词对应一个目标单词,需要进行正则化,以使得
- 对训练时的目标函数作如下更改:。该函数的目的有二:一,同之前一样最小化交叉熵;二,最小化注意力向量与外部的词对齐向量之间的差异
Incorporating Structural Alignment Biases(Cohn et.al.,2016)
通过统计词对齐算法,我们发现对齐本身会有一定的偏差(bias)。
- position bias: 相关的位置对对齐提供了大量的信息
- fertility/coverage: (生育/覆盖) 一些词会在目标句中生成多个词来保证所有的源单词都会被覆盖到
- bilingual symmetry: 双语对称性, 互为源语言与目标语言的两种语言,词对齐是对称的
针对 position bias, 我们需要在创建注意力模型的时候输入位置信息。对于非递归架构来说这种方法更加有效(CNN?)
position encoding 的方法也有各式各样的。
针对 fertility/coverage, 我们的想法是对于目标语言,同样有 ,即同注意力的 softmax 类似,同一源单词的注意力权重在目标句上的和应当近似于1。因此,我们可以用这样的正则项来作为训练的目标函数:。这种优化方法由于有一个预先假设,但是在实际情况中这种假设不一定成立,一种更加 general 的方式是,使用一个神经网络来学习单词的”生育”: ,然后用 fertility 项来替代原式中的 1。
针对 bilingual symmetry, 我们在训练的时候可以添加一项路径奖励,来奖励那些能够生成具有对称性的注意力。