Perceptron
感知机是神经网络最基本的元件之一, 是一个加权分类器。
基本的感知机算法如下:
当大于某个阈值时,输出1,反之输出0。
逻辑门实现
我们可以用最基本的感知机来实现一些基本的逻辑门。
首先我们来看一下 AND 函数的真值表:
| x1 | x2 | x1 AND x2 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
AND 函数是线性可分的:在一个二维空间里,横坐标为x1, 纵坐标为 x2, 我们可以用一条直线来将空间分为两部分,分别表示激活状态与非激活状态。同理,OR 函数也是线性可分的。
我们使用如下函数来定义我们的感知机加权计算u(x):
激活的阈值,当函数值小于1时,不激活;反之大于等于1时激活。
同理,我们可以根据如下的真值表写出 OR 的定义:
| x1 | x2 | x1 OR x2 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
感知机权重:
阈值为大于0, 小于等于0.5的任意实数。实际上,我们可以将阈值从不等式的右边拿到左边,这样一来我们就可以使用一个截距项来处理不同情况下的阈值。
XOR 是另外一种情况:我们在空间中没有办法使用线性的分割线将空间分为两个部分。用感知机的解决方案是:复合多层感知机(MLP),来应对非线性的问题。首先,我们写出 XOR 的真值表:
| x1 | x2 | x1 XOR x2 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
注意到如下事实:x1 XOR x2 = ((NOT x1) AND x2) OR (x1 AND (NOT x2)),可以写真值表验算一下。
我们实际上可以将 XOR 操作分解为两步: 第一步计算两个 AND, 第二部计算上一步的OR。NOT操作,我们可以用负的权重来实现。
由此,我们可以写出如下的感知机分解式子:
这是一个两层的感知机,其结构如下图:
另一种分解方式为: x1 XOR x2 = (x1 NAND x2) AND (x1 OR x2)
参数的学习
我们可以通过梯度下降法来学习参数:
即:损失函数相对于参数的导数。
MLP 的一般使用思路如下:
- 初始化 MLP 参数
- 给定训练特征x,然后计算 MLP 的输出 y
- 将 y 与正确的目标 t 作对比,得到误差量 (error quantity)
- 根据误差量,使用梯度下降法对 MLP 的参数进行修正
- 重复2-5,直至收敛
我们的学习目标一般是最小化损失函数,常用的损失函数有均方根误差(Mean Square Error, MSE)
基于 MLP 的语言模型
n-gram 角度的语言模型:输入为,输出为单词的概率,我们用一个函数来描述:。
函数角度的语言模型:输入为 prefix 字符串,输出为一个概率分布: 。
我们使用 one-hot 编码来编码单词,再将单词按照顺序连接成一个大的向量,这样子我们就可以将单词表示为向量形式。同理,我们的概率分布也是向量形式。这样,我们在数学上就可以用 MLP 来处理,因为 MLP 在前向的运算实际上就是矩阵乘法的形式。在输出层,我们使用 softmax 函数来处理每个单词的概率分布。
对于 n-gram 模型, 我们通常可以使用如下的神经网络进行处理:
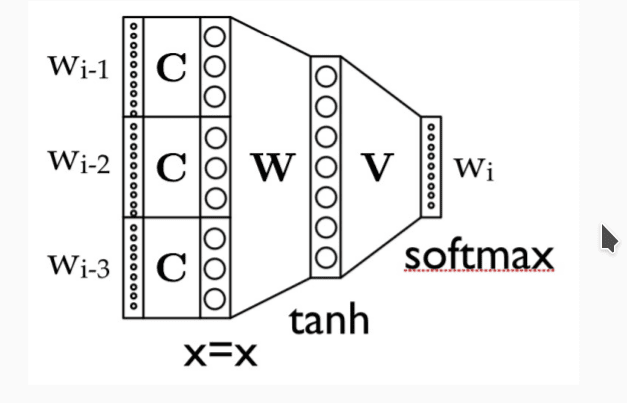
首先,对每个 one-hot 向量,使用矩阵 C 进行压缩编码得到词嵌入(embedding);然后使用矩阵 W 来计算 ngram 的完整表示向量,最后,矩阵 V 被用来计算最终的概率分布。
Recurrent Networks
引入递归神经网络的原因有以下几点:
- n-gram 模型对上下文信息利用不充分
- 上述的 MLP 模型虽然能够对比较广的上下文进行建模,但是其大小是固定的
- 与此相反,语言学的角度来说,需要的上下文范围实际上很大
基于这些原因,人们提出了 RNN 模型:
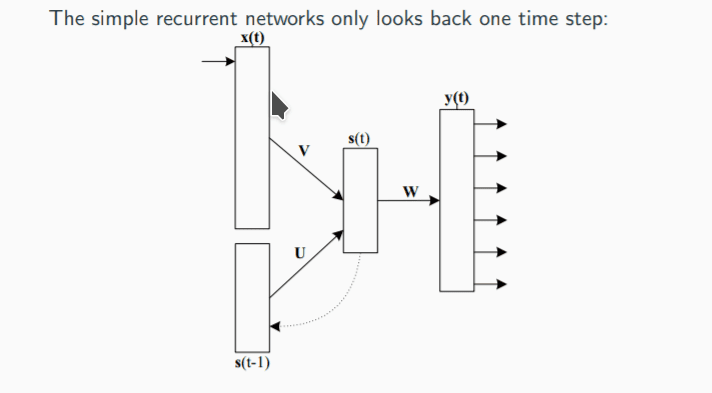
这是一个最简单的,回看一步的 RNN 网络结构。向量 x 是时刻 t 的输入,这里我们可以理解为 one-hot 的单词。向量 y 是时刻 t 的输出向量,向量 s 是时刻 t 的隐层,对于每个时刻而言,输入都是上一时刻的 s 与 x 向量拼接后的向量。
我们可以看出,该网络递归的利用了所有以前的信息,从而,我们在使用 RNN 建立语言模型的时候不再需要马尔科夫假设。
训练网络的过程如下:
- 首先,我们随机初始化参数矩阵 U, V, W, 隐层随机初始化。
- 对于任意的时刻 t, 我们都将其作为普通的 MLP进行处理,只不过我们的输入是 x 与 时刻t-1 的 s 的复合
- 我们定义训练的目标是给定历史序列,计算下一个单词的概率分布,所以错误信号定义为 ,其中 是 one-hot 编码。
- 我们使用如上方法,来在给定的训练集上训练网络。
Backpropagation through time(BPTT)
再进一步,我们需要将我们的反向传播前推至任意长度,以实现对历史上下文信息的利用。实际上,我们可以把这个过程看做是当前的单词的概率是之前 n 个单词的函数,所以反向传播需要对以前的时刻的参数进行更新。从另一个角度来看,我们可以将 BPTT 版本的 RNN 看作是一个沿着时间轴展开的大型 MLP。
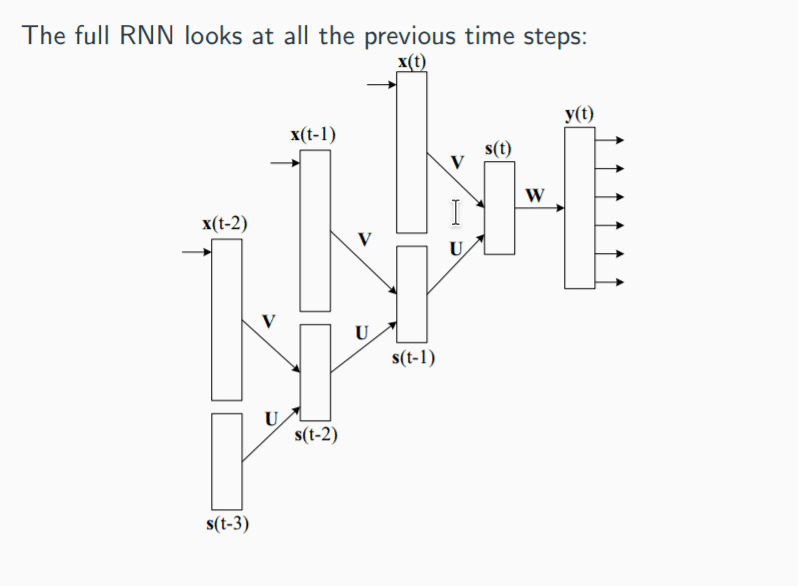
首先,我们定义一下公式:
首先,令向量对于 softmax 函数而言,对第 i 分类的第 j 个输入我们有
注意,i 与 j 不一定相等。令使用除法求导法则我们有
当 的时候,第一项偏导数为 ,从而我们有
反之,第一项偏导数为0,我们有
使用复合函数求导法则,我们可以得到 W, s 关于 a 的偏导:
而对于 s 而言,它又可以传播到前一个 s’:
以此类推。
我们可以任意地回溯时间直至序列的开头,但是由于我们通常采用诸如 sigmoid, tanh 之类的激活函数,导数在数值上往往小于1,从而带来了梯度消失的风险:反向传播会以指数形式放大/缩小导数,由于反向传播过远,导致梯度在较长的时刻之前接近于0,从而无法传播。RNN 的中远时刻的信息,要么非常强,要么非常弱。
LSTM
为了解决梯度消失的问题,LSTM 作为 RNN 的一个变种被提出。LSTM 的基本思路是:保持很长一段时间的信息不变,从而系统可以从较远的输入中获取信息。
与普通的 RNN 不同, LSTM 有一个额外的记忆层来存储长时间的记忆。LSTM 由如下四个元件组成:
- Input gate: 用于控制输入是否被存储到记忆中
- Output gate: 用于控制当前激活的记忆向量是否传递至输出层
- Forget gate: 控制记忆向量是否清零
- Memory cell: 存储当前的记忆向量
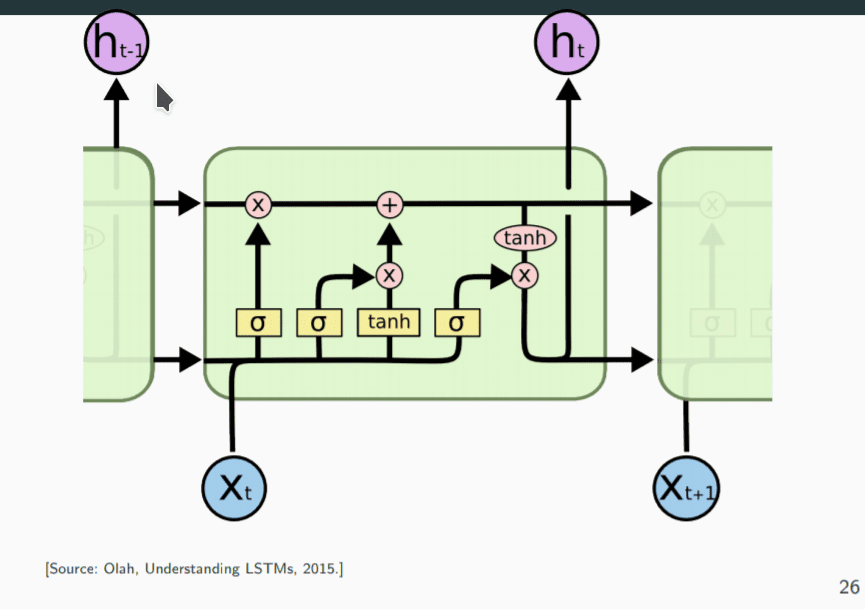
图中, 表示 sigmoid 函数, 加号表示向量拼接,乘号表示向量乘法。h 表示输出。
从左到右:
- 首先,隐层向量与输入向量在遗忘门经过sigmoid函数转化为 0-1 区间的数,接近 0 则表示遗忘,接近 1 则表示记忆。
这一步是对记忆层进行遗忘,遗忘的依据是当前的输入向量与隐层 - 第二步是输入门,输入门由一个 sigmoid 与一个 tanh 层组成,对当前的输入(隐层向量与输入向量的拼接)进行筛选,tanh 与 sigmoid 分别做决策,然后 pointwise multiplication 综合两者,都重要的记忆留下,其余筛去。
- 从输入门往上,将经过遗忘的记忆向量与经过输入门筛选的向量进行 pointwise addition, 激活/强化当前的记忆
- 第三步是输入门右边的输出门,由一个 sigmoid 激活原来的隐层向量与输入向量的拼接,由一个 tanh 处理记忆,然后两者point-wise相乘,得到当前时刻的输出。这个输出同时会保存,作为下一时刻的隐层输入。
LSTM 用于解决梯度消失的思路是:记忆层的传递本质是一个线性函数,所以在这个层面没有梯度消失的问题,导数可以一直传递下去。对于控制门而言,它们能够随着训练学习到何时应当开门激活,何时应当屏蔽门的输入。这种设计提升了网络的复杂度,也能更精细地控制历史信息。